Metadata are data that identify other data or datasets; so, they are data that specify the purpose of an information structure.

In a simple comparison: If the information structures were jars of food and the document were the shelves where those jars are, the metadata would be the labels that tell us what is inside each jar, the preferred date of compsuntion, what calories they contain, and so on. These labels not only make it easier to manage the items without having to analyse or open them. They also provide extra information that an analysis would not necessarily provide ("the favourite jam of Mom", for example).
In a PDF document, metadata can tag the whole document, some structures and groups of structures. Each each one may or may not carry its own metadata.
Warning: We should not mistake interactivity for metadata. They are distinct domains. However, in certain programmes, some structures that help to use the document by providing information about its parts (annotations, page thumbnails, structural information, etc.) are treated and considered somehow as if they were metadata
The use of metadata in early versions of the PDF format was fairly primitive, restricted to things like the name of the document, who created it and when. Only since version 1.4 of the format, it was added the ability to tag with their own metadata individual components within documents (e.g. images).
Format of metadata in a PDF
In a PDF, metadata in the strict sense can be added in two ways:
1. The document info dictionary

This was the original way of incorporating metadata when the first version of the PDF format was created. It only allows reporting general data about the document. In Acrobat it can be accessed through the "Properties" menu.
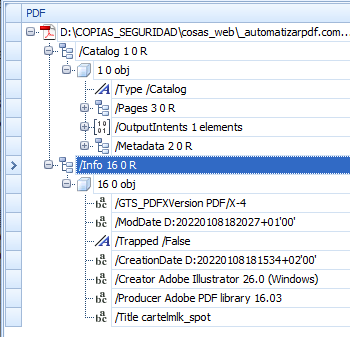
In the trailer of a PDF there is an entry called "Info", which is a document information dictionary. There, in the form of "key/value" pairs (as in all dictionaries), the following optional information about the document can be entered:
- Title: The title of the document. In the absence of any other instruction, many programs use the name of the file from which the PDF was created.
- Author: The person who created the document.
- Subject: What the document is about.
- Keywords: A set of words identifying the content of the document.
- Creator: The software with which the document was initially created (e.g. "
Adobe InDesign 16.2 (Windows)". - Producer: If the PDF was converted from another format, the software that performed the conversion (e.g. "
Adobe PDF Library 15.0"). - Creation date: When the document was created.
- Modification date: When the document was last modified.
- Trapped: Whether the document has trapping applied or not. The third possibility ("
Unknown") is the default value.
The document info dictionary allows the addition of other metadata as long as the key/value format is respected. Those programs that do not have instructions about these metadata will ignore them. Some standards add their identifier keys here (although they are always duplicated in a more detailed way in the corresponding catalog metadata stream discussed in the section below).
Of these keys, the main one is: "GTS_PDFXVersion", which indicates that the document is a PDF/X document. The PDF/X variant to which it belongs is indicated in the associated value (which can only be one of the supported values, e.g. "PDF/X4").
Warning: The existence of this or any other metadata referring to a PDF standard does not indicate that the document complies with this standard. It only means its creators intended it to comply with the standard.
2. The metadata streams
In version 1.4 of the PDF format it was added the possibility of adding more metadata in other areas of the document. With this method, any content structure in a PDF that has the form of a stream or dictionary can have metadata attached to it.
It can be applied to elements such as pages, forms, embedded fonts, files, or colour profiles, and especially images. Besides, it can be applied to the whole document itself.

In this case, when the metadata refer to the whole document, it must go as a metadata stream in the dictionary called "Catalog". It is usual that this general information duplicates some of the information contained in the document info dictionary, which is in fact an obsolete structure that is maintained for backwards compatibility reasons.
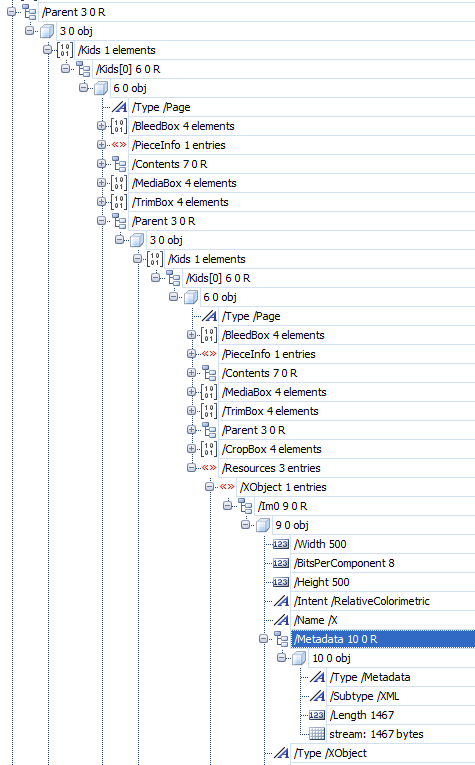
Metadata for specific structures, such as images, should be as close to them as possible to avoid ambiguities in their interpretation.
Metadata in these metadata streams should always be presented in a variant of XML called XMP, developed by Adobe. This ensures that they will be correctly identified and interpreted.
Discrepancies between the data of the the two areas
If there are differences between the general metadata in the document info dictionary and the metadata stream in the catalog dictionary, the data with the latest modification date should prevail.
PieceInfo
PDF documents have the ability to incorporate proprietary data from other programs. This happens, for example, when Illustrator or Photoshop are asked to save a PDF preserving their editing capabilities. It is also the case with modern versions of Adobe InDesign that allow us to import and export comments in a PDF.
These are incorporated in the PDF as metadata by means of dictionaries called "PieceInfo", which are distributed throughout the document.
Warning: It is this ability to incorporate native data from other applications that gave rise to the idea that PDF is a native Illustrator format and that Illustrator was a PDF editor. Both are not true.
PDF/X specifications and metadata
In their first versions, the PDF/X specifications only required the presence of a few general metadata: document title, creation and modification date. In addition, the value "Unknown" in the "Trapped" key was prohibited and the level of the PDF/X standard to which the document conformed had to be declared.
From the PDF/X-4 version onwards, the use of a general metadata flow in XMP format in the catalog dictionary is mandatory. On the other hand, the presence of such data in the document information dictionary became optional (although, if it exists, it must be identical in both areas).
PDF/A specifications and metadata
It is mandatory for a PDF/A to have a metadata stream in XMP format with the entry "metadata" in the catalog dictionary of the document. The aim is to ensure that the document contains the necessary general information about itself.
Other PDF specifications and metadata
PDF/E and PDF/UA documents have the same metadata requirements that PDF/A documents have.
[© Gustavo Sánchez Muñoz, 2025] Gustavo Sánchez Muñoz (also identified as Gusgsm) is the author of the content of this page. Its graphic and written content can be shared, copied and redistributed in whole or in part without the express permission of its author with the only condition that it cannot be used for directly commercial purposes (that is: It cannot be resold, but it can form part as reasonable quotations in commercial works) and the legal terms of any derivative works must be the same as those expressed in this statement. The citation of the source with reference to this site and its author is not mandatory, although it is always appreciated.